HOME Features Docs ASPLOS 2023 Tutorial GNN-Dataflow Code Resources SST Integration Flexagon
ASPLOS 2023 STONNE Tutorial
Date: 26th March 2023
Venue: Vancouver, BC, Canada
Important: ASPLOS requires attendees to specify their intention to attend the tutorial while registering for the conference.
ORGANIZERS
Francisco Muñoz-Martínez (Universidad de Murcia)
Raveesh Garg (Georgia Institute of Technology)
Tushar Krishna (Georgia Institute of Technology)
José L. Abellán (Universidad de Murcia)
Manuel E. Acacio (Universidad de Murcia)
OVERVIEW
The design of specialized architectures for accelerating the inference procedure of Deep Learning (DL) is a booming area of research nowadays. While first-generation systolic-based accelerator proposals used simple fixed dataflows tailored for dense Deep Neural Networks (DNNs) applications, more recent architectures like MAERI or SIGMA have argued for flexibility to efficiently support a wide variety of layer types, dimensions, and sparsity. In addition, the recent appearance of Graph Neural Networks (GNNs) applications has resulted into multi-phase accelerators that combine the execution of multiple kernels in a pipelined manner, making the architectures much more complex.
As the complexity of these accelerators grows, the analytical models currently being used for design-space exploration are unable to capture execution-time subtleties, leading to inexact results in many cases. This opens up a need for cycle-level simulation tools to allow for fast and accurate design-space exploration of DL accelerators, and rapid quantification of the efficacy of architectural enhancements during the early stages of a design. To this end, STONNE (Simulation Tool for Neural Network Engines) is a cycle-level microarchitectural simulation framework that can plug into any high-level DL framework as an accelerator device and perform full-model evaluation (i.e. we are able to simulate real, complete, unmodified DNN models) of state-of-the-art systolic and flexible DNN accelerators, both with and without sparsity support. STONNE is developed by the University of Murcia and the Georgia Institute of Technology and is open-sourced under the terms of the MIT license.
In this tutorial we demonstrate how STONNE enables research on DNNs accelerators by means of several use cases that range from the microarchitectural networks on-chip present in DNN accelerators to the scheduling strategies that can be utilized to improve energy efficiency in sparse accelerators. Further, we present OMEGA, another framework built on top of STONNE that enables the exploration of dataflows for accelerators for multi-phase GNN applications which are gaining popularity in the AI and HPC community.
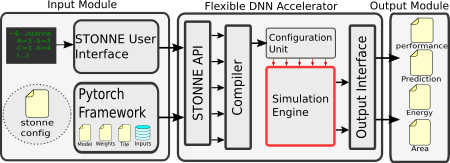
Figure above shows a high-level view of STONNE with its three major modules for full-model simulation flows. The input module feeds the simulator with the values to be computed along with the DNN dataflows and the hardware configuration. Then, the simulation engine performs the cycle-level simulation using its internal simulated microarchitectural building blocks. Finally, the output module returns the statistics of the simulation. For more details, please refer to the features of STONNE.
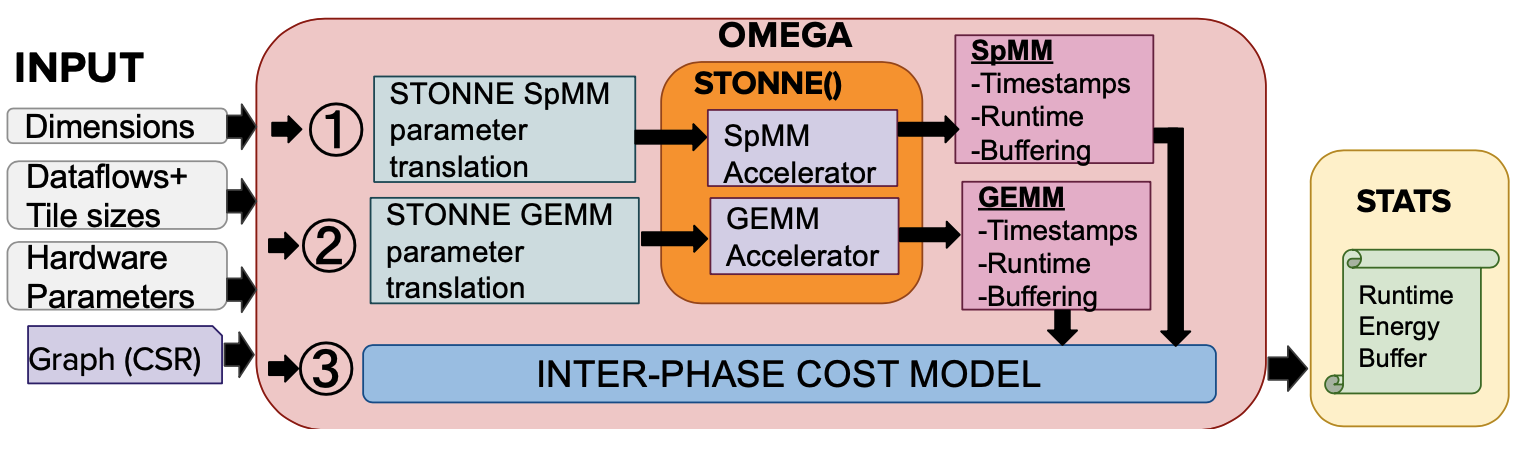
Figure above shows a brief overview of OMEGA framework built on top of STONNE. OMEGA computes GNNs which consist of an SpMM followed by a GEMM phase. STONNE simulator accurately computes the timestamps and buffer accesses for individual phases and these are fed into the inter-phase cost model which computes the final metrics considering the inter-phase (between the phases) dataflow/pipelining strategies. Please refer to the GNN Dataflows page for more details.
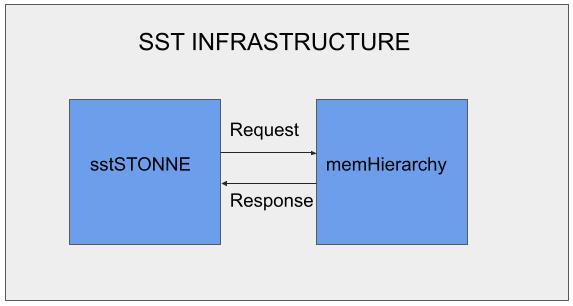
Figure above shows an overview of STONNE connection to the memory hierarchy. The requests go through the cache hierarchy instead of scratchpad, thus providing an ability to simulate shared memory heterogeneous systems.
SCHEDULE
Tutorial video recording
Link to timestamps of individual sections is included in the table below
| Time PT(pm) | Agenda | Presenter | Slides | Video (timestamps) |
|---|---|---|---|---|
| 1:40-2:00 | A Communication-Centric Approach to Flexible Accelerator Design | Jose Luis | Welcome and PART1 | Link to timestamp |
| 2:00-2:20 | Cycle accurate simulation motivation and Overview of STONNE | Jose Luis | PART2 | Link to timestamp |
| 2:20-3:20 | (Hands-on) STONNE | Francisco | PART3 | Link to timestamp |
| 3:20-3:40 | Coffe Break | |||
| 3:40-4:10 | (Hands-on) SST-STONNE | Francisco | Included in PART3 | Link to timestamp |
| 4:10-4:40 | GNN Dataflow Taxonomy and (Demo) OMEGA framework. | Raveesh | PART4 | Link to timestamp |
| 4:40-5:00 | Roadmap for future research/development | Tushar | PART5 | Link to timestamp |
Docker Image
docker run -it stonnesimulator/stonne-simulators
git clone https://github.com/stonne-simulator/tutorials (inside docker)
CODEBASES
STONNE
https://github.com/stonne-simulator/stonne
OMEGA
https://github.com/stonne-simulator/omega
SST-STONNE
https://github.com/stonne-simulator/sst-elements-with-stonne
PUBLICATIONS
STONNE
Francisco Muñoz-Martínez, José L. Abellán, Manuel E. Acacio, and Tushar Krishna. Stonne: Enabling cycle-level microarchitectural simulation for dnn inference accelerators. In 2021 IEEE International Symposium on Workload Characterization (IISWC), 2021. (pdf)
OMEGA
Raveesh Garg, Eric Qin, Francisco Muñoz-Martínez, Robert Guirado, Akshay Jain, Sergi Abadal, José L Abellán, Manuel E Acacio, Eduard Alarcón, Sivasankaran Rajamanickam, and Tushar Krishna. Understanding the Design-Space of Sparse/Dense Multiphase GNN dataflows on Spatial Accelerators. In 2022 IEEE International Parallel and Distributed Processing Symposium (IPDPS), 2022. (pdf)
Flexagon
Francisco Muñoz-Martínez, Raveesh Garg, Michael Pellauer, José L. Abellán, Manuel E. Acacio, and Tushar Krishna. 2023. Flexagon: A Multi-dataflow Sparse-Sparse Matrix Multiplication Accelerator for Efficient DNN Processing. In Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3 (ASPLOS 2023). Association for Computing Machinery, New York, NY, USA, 252–265. https://doi.org/10.1145/3582016.3582069 .(pdf)
CITATIONS
If you use STONNE or OMEGA framework in your research or if you run on flexagon accelerator model in SST-STONNE. Please cite-
STONNE
@INPROCEEDINGS{STONNE21,
author = {Francisco Mu{\~n}oz-Mart{\'i}nez and Jos{\'e} L. Abell{\'a}n and Manuel E. Acacio and Tushar Krishna},
title = {STONNE: Enabling Cycle-Level Microarchitectural Simulation for DNN Inference Accelerators},
booktitle = {2021 IEEE International Symposium on Workload Characterization (IISWC)},
year = {2021},
volume = {},
number = {},
pages = {},
}
OMEGA
@inproceedings{garg2021understanding,
title={Understanding the Design-Space of Sparse/Dense Multiphase GNN dataflows on Spatial Accelerators},
author={Garg, Raveesh and Qin, Eric and Mu{\~n}oz-Mart{\'\i}nez, Francisco and Guirado, Robert and Jain, Akshay and Abadal, Sergi and Abell{\'a}n, Jos{\'e} L and Acacio, Manuel E and Alarc{\'o}n, Eduard and Rajamanickam, Sivasankaran and Krishna, Tushar},
booktitle={2022 IEEE International Parallel and Distributed Processing Symposium (IPDPS)},
year={2022}
}
Flexagon
@inproceedings{munoz2023flexagon,
title={Flexagon: A Multi-Dataflow Sparse-Sparse Matrix Multiplication Accelerator for Efficient DNN Processing},
author={Mu{\~n}oz-Mart{\'\i}nez, Francisco and Garg, Raveesh and Pellauer, Michael and Abell{\'a}n, Jos{\'e} L and Acacio, Manuel E and Krishna, Tushar},
booktitle={Proceedings of the 28th ACM International Conference on Architectural Support for Programming Languages and Operating Systems, Volume 3},
pages={252--265},
year={2023}
}
CONTACT
Francisco Muñoz-Martínez - francisco.munoz2@um.es
ACKNOWLEDGMENTS
This work was supported by NEC Laboratories Europe, Project grant PID2020-112827GB-I00, by MCIN/AEI 10.13039/501100011033, RTI2018-098156-B-C53 (MCIU/AEI/FEDER,UE), NSF OAC 1909900 and US Department of Energy ARIAA co-design center. The work was also supported by Grant RYC2021-031966-I funded by MCIN/AEI/ 10.13039/501100011033 and by the “European Union NextGenerationEU/PRTR”. F. Muñoz-Martínez was supported by grant 20749/FPI/18 from Fundación Séneca.